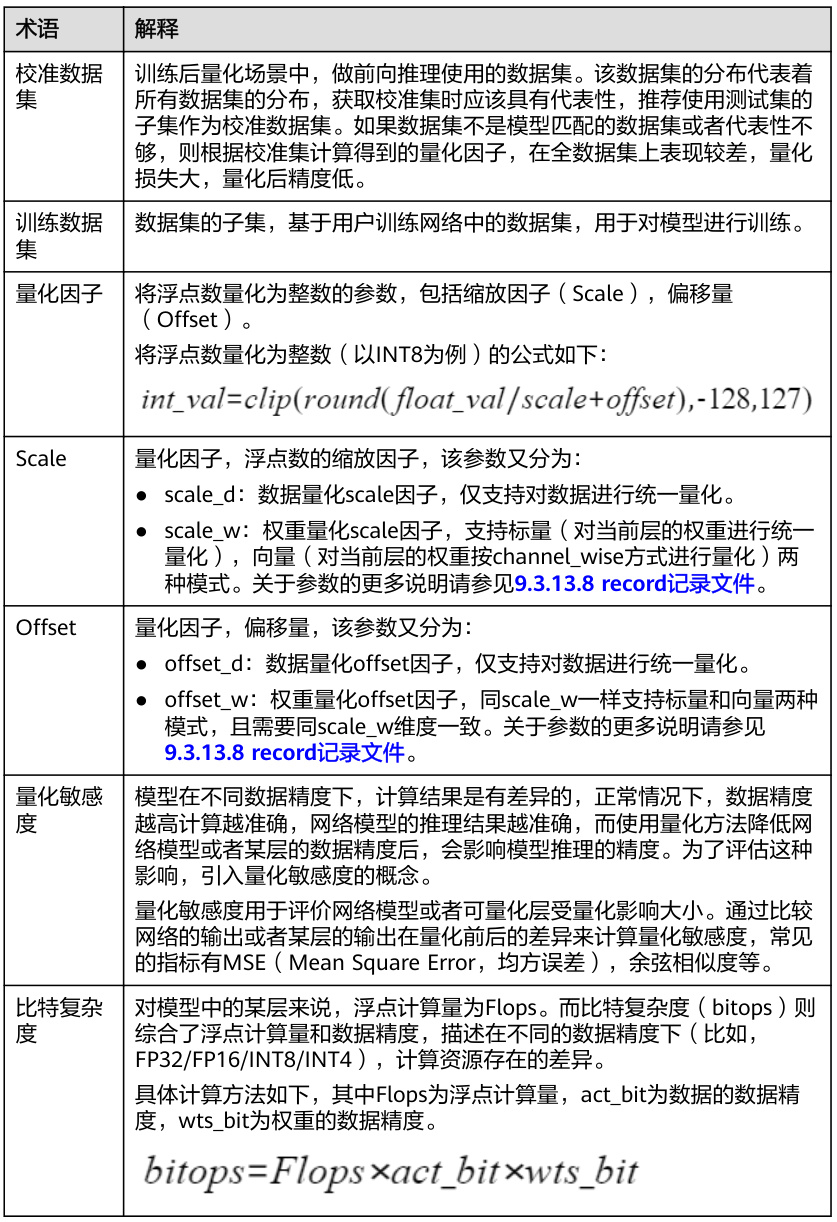
在深度学习中,校准数据集(Calibration Dataset)是一个用于模型量化和优化过程中的关键概念。它主要用于确保模型在量化后仍能保持良好的性能和泛化能力。以下是对校准数据集的详细解释:
1. 校准数据集的定义与作用
校准数据集是用于模型量化过程中的一个数据集,其主要作用是帮助模型在量化后保持较高的精度和泛化能力。在深度学习中,模型的量化(如INT8量化)可能会导致模型性能下降,因此需要通过校准数据集来调整模型的量化参数(如缩放因子和偏移量),以确保模型在量化后仍能保持较高的性能。
2. 校准数据集的生成与使用
校准数据集通常是一个可迭代对象,可以是生成器对象,用于生成少量的样本数据。这些样本数据用于校准模型的量化参数。例如,在生成校准数据集时,可以使用随机生成的数据或从训练数据集中抽取的子集。
3. 校准数据集的特性
- 代表性:校准数据集应代表整个数据集的分布,以确保模型在量化后仍能保持良好的泛化能力。
- 样本量:校准数据集通常使用少量样本进行校准,以减少计算开销。
- 评估与优化:校准数据集的选择和优化是模型量化过程中的重要步骤。可以通过评估校准数据集的分布与训练数据集的分布之间的差异,来优化模型的量化参数。
4. 校准数据集的应用场景
校准数据集广泛应用于深度学习模型的量化和优化过程中,特别是在模型部署和推理阶段。例如,在模型量化过程中,校准数据集用于调整模型的量化参数,以确保模型在量化后仍能保持较高的性能。
5. 校准数据集与其他数据集的区别
校准数据集与训练集、验证集和测试集不同,其主要作用是用于模型的量化和优化,而不是用于模型的训练或评估。校准数据集通常不用于模型的训练或评估,而是用于模型的量化和优化。
6. 校准数据集的挑战与解决方案
校准数据集的选择和优化是一个复杂的过程,涉及多个方面,如数据分布的匹配、模型性能的评估等。为了解决这些问题,研究人员提出了多种方法,如使用统计方法、优化算法等来优化校准数据集的性能。
总结
校准数据集在深度学习中是一个重要的概念,用于模型的量化和优化过程。它通过提供代表性的样本数据,帮助模型在量化后保持较高的性能和泛化能力。校准数据集的生成、使用和优化是模型量化和优化过程中的关键步骤。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!