Huffman编码是一种广泛使用的无损数据压缩算法,其核心思想是根据字符出现的频率来分配编码长度,以实现数据压缩。
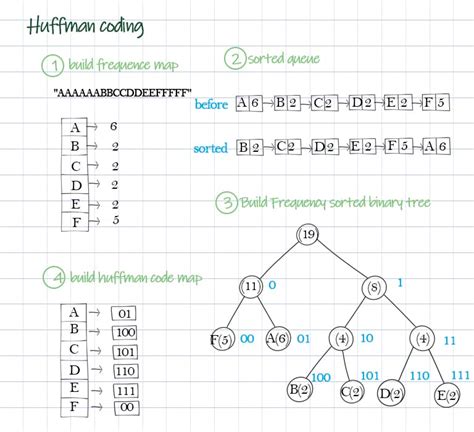
Huffman编码由David A. Huffman于1952年提出,其核心原理是为出现频率高的字符分配较短的编码,而出现频率低的字符则分配较长的编码。这种编码方式能够有效减少数据的存储空间,同时保持数据的完整性。
Huffman编码的实现过程通常包括以下几个步骤:首先,统计字符的出现频率;其次,根据频率构建一个优先级队列,将频率最低的字符合并为新的节点,重复此过程直到生成一个完整的二叉树(Huffman树);最后,根据生成的树结构生成编码表,并对数据进行编码或解码。Huffman编码生成的编码是前缀编码,即没有一个编码是另一个编码的前缀,这使得解码过程更加简单和高效。
Huffman编码的应用非常广泛,包括文件压缩、图像压缩、通信和数据存储等领域。例如,在JPEG和MP3等格式中,Huffman编码被用于实现高效的压缩和解压。此外,Huffman编码在计算机科学和信息论中具有重要地位,是数据压缩领域的基础技术之一。
Huffman编码是一种基于贪心算法的最优编码方法,通过构建二叉树来实现最小化平均编码长度的目标。尽管Huffman编码在字符频率分布不均衡时效果显著,但在字符频率均衡的情况下,其压缩效果可能不如其他方法。然而,Huffman编码的实现相对简单,且在实际应用中具有较高的效率和可靠性。
Huffman编码是一种基于字符频率的无损数据压缩算法,通过为高频字符分配短编码、低频字符分配长编码,实现数据压缩和解压。其核心思想是通过构建Huffman树来生成编码表,并通过编码和解码过程实现数据的压缩和恢复
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!