FP-Tree算法是一种用于频繁模式挖掘的高效算法,它通过构建FP-Tree(Frequent Pattern Tree)结构来避免传统Apriori算法中生成大量候选集的问题,从而提高效率。FP-Tree算法的核心思想是通过压缩存储频繁项集信息,递归挖掘频繁模式,从而实现高效的数据挖掘。
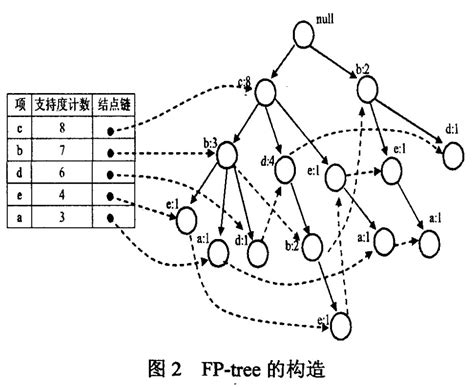
FP-Tree算法的基本结构包括一棵FP树和一个项头表。FP树的根节点通常表示为空集,每个节点包含项名、计数和节点链接。项头表按支持度递减排序,记录每个项名及其对应的节点链接。FP树的构建过程通常包括两次扫描事务数据库:第一次扫描统计每个项的支持度,并筛选出支持度高于阈值的项;第二次扫描将事务数据插入FP树中,构建完整的FP树。
FP-Tree算法的核心是FP-Growth算法,它通过递归挖掘生成频繁模式。FP-Growth算法通过条件模式基(CPB)和后缀模式(PostModel)生成频繁模式。算法通过递归处理每个表头项,生成新的CPB和PostModel,直到CPB为空。FP-Growth算法通过递归挖掘生成频繁模式,相比Apriori算法,它避免了生成大量候选集的问题,提高了效率。
FP-Tree算法在处理大规模数据时仍需考虑内存和计算效率,可通过并行计算和优化算法进一步提升性能。FP-Tree算法在关联规则挖掘、分类、聚类等任务中具有广泛应用。
FP-Tree算法是一种高效的数据挖掘算法,通过构建FP树结构,有效挖掘频繁模式,避免了传统Apriori算法多次扫描数据库和生成大量候选集的问题
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!