FP-growth算法是一种用于挖掘频繁项集的高效算法,它通过构建FP树(Frequent Pattern Tree)来压缩数据集,从而提高挖掘效率。该算法由Han等人于2000年提出,旨在解决传统Apriori算法在大数据集上的效率问题。
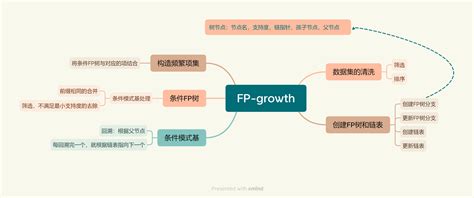
FP-growth算法的核心思想是通过构建FP树来表示数据集中的频繁项集,并从FP树中挖掘频繁项集。与Apriori算法不同,FP-growth算法不需要生成候选集,从而显著提高了效率。FP-growth算法通过递归构建FP-tree并从中挖掘频繁项集,其工作原理包括数据预处理、FP树的构建、频繁项集的挖掘以及条件模式基的生成。
FP-growth算法的基本原理包括:首先扫描数据集计算项的支持度,去除低支持度项;然后构建FP-tree,压缩数据;接着递归挖掘频繁项集。构建FP-tree需两次扫描数据集,第一次计算支持度并排序,第二次插入事务。FP-growth算法通过条件模式基和条件树的构造,避免了Apriori算法中多次扫描数据库和生成大量候选集的问题,提高了效率。
FP-growth算法在处理大规模数据集时具有更高的效率,尤其适用于数据挖掘领域的广泛应用。该算法在处理大规模数据集时能够显著减少对数据库的扫描次数和计算量,从而提高挖掘效率。
FP-growth算法是一种高效的频繁项集挖掘算法,通过构建FP树和递归挖掘频繁项集,显著提高了数据挖掘的效率和性能
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!