Apriori算法是一种用于关联规则学习的无监督机器学习算法,主要用于挖掘数据中频繁出现的项集和关联规则。该算法通过识别数据中不同项组之间的频繁模式、联系和依赖关系,帮助用户发现数据中的潜在规律和关联性。
核心思想与原理
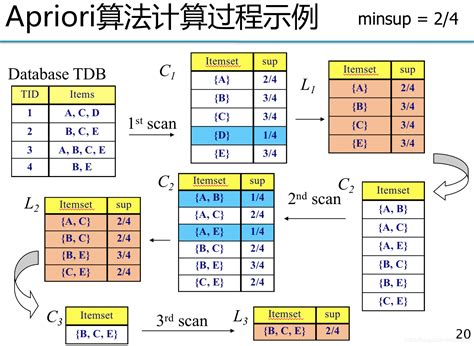
Apriori算法的核心思想是基于“先验性质”(Apriori Property),即如果一个项集是频繁的,那么它的所有子集也是频繁的;如果一个项集是非频繁的,那么它的所有超集也是非频繁的。这一性质使得算法可以通过剪枝操作减少不必要的计算,从而提高效率。
算法的工作流程通常包括以下几个步骤:
- 确定最小支持度阈值:设定一个最小支持度阈值,用于过滤掉不常见的项集。
- 生成频繁项集:通过扫描数据库,找出满足最小支持度的项集,生成频繁项集。
- 生成候选集:使用当前的频繁项集生成更大项集的候选集。
- 迭代过程:重复生成候选集和筛选频繁项集的过程,直到无法生成新的频繁项集。
- 生成关联规则:从频繁项集中生成关联规则,并根据最小置信度阈值筛选出强关联规则。
应用领域
Apriori算法广泛应用于多个领域,包括:
- 市场篮子分析:通过分析顾客的购买行为,发现商品之间的关联关系,如“啤酒和尿布”的经典案例。
- 推荐系统:基于用户行为数据,推荐相关产品或服务。
- 医疗保健:用于疾病预测和医疗数据分析。
- 网络安全:用于检测异常行为和入侵检测。
优点与缺点
优点:
- 算法简单易懂,易于实现和理解。
- 适用于多种数据类型和场景,具有良好的可扩展性。
- 通过剪枝操作减少计算复杂度,提高效率。
缺点:
- 计算成本较高,尤其是在处理大规模数据时,生成候选集和扫描数据库的开销较大。
- 对最小支持度和置信度阈值的选择敏感,可能影响结果的准确性。
- 传统Apriori算法在处理大规模数据时存在性能瓶颈,因此出现了改进算法(如FP-Growth)以提高效率。
总结
Apriori算法是一种经典的数据挖掘算法,广泛应用于关联规则挖掘和频繁项集分析。尽管存在一些局限性,但其核心思想和方法在数据挖掘领域具有重要价值,并在多个领域中发挥着重要作用
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!