预训练范式是近年来人工智能领域中一种重要的模型训练方法,尤其在自然语言处理(NLP)和计算机视觉(CV)等任务中得到了广泛应用。它通过在大规模数据集上进行初始训练,使模型能够学习到通用的特征表示,然后在特定任务上进行微调,从而实现对下游任务的高效适应。
预训练范式的定义与核心思想
预训练范式的核心思想是利用大量无标注数据训练一个通用模型,使其能够捕捉到语言或视觉的深层次特征。这种方法最初由BERT(Bidirectional Encoder Representations from Transformers)提出,并迅速成为自然语言处理领域的基础范式。随后,类似的范式也被应用于计算机视觉和其他领域,例如VisionPAD。
具体来说,预训练范式通常包括以下步骤:
- 大规模数据预训练:在海量无标注数据上训练模型,使其学习到语言或视觉的通用特征表示。
- 任务特定微调:在少量标注数据上对预训练模型进行微调,以适应特定任务的需求。
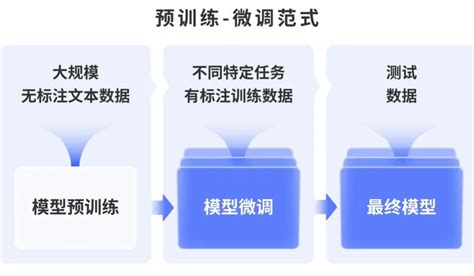
预训练范式的分类
根据不同的应用场景和技术特点,预训练范式可以分为以下几种主要类型:
1. 预训练-微调范式
这是最经典的预训练范式,也是目前应用最广泛的一种形式。其流程如下:
- 预训练阶段:在大规模语料库(如Wikipedia、书籍等)上训练模型,使其学习语言的深层结构和语义信息。
- 微调阶段:在特定任务的数据集(如SQuAD、GLUE等)上进一步优化模型参数,以适应下游任务的需求。
例如,BERT通过掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)任务进行预训练,然后在下游任务中进行微调。
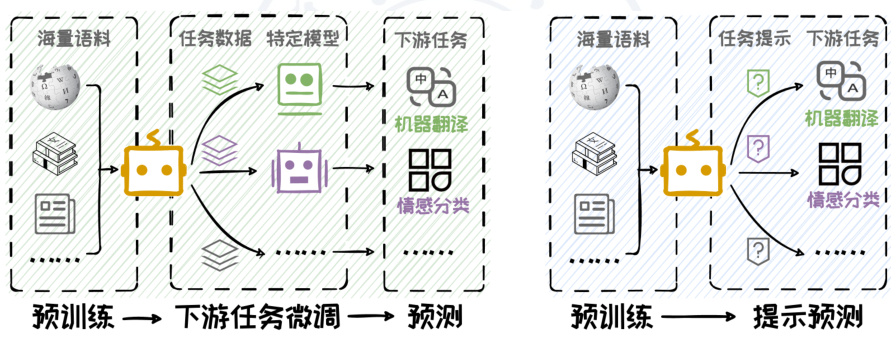
2. 预训练-提示范式
提示学习是一种新兴的预训练范式,它不依赖于传统的微调过程,而是通过设计特定的提示(prompt)来引导模型完成任务。例如,GPT-3通过提示学习实现了多种自然语言处理任务,而无需额外的微调。
这种方法的优势在于减少了对标注数据的依赖,同时提高了模型的泛化能力。例如,在机器翻译任务中,可以通过简单的提示词引导模型生成翻译结果。
3. 半监督预训练
半监督预训练结合了有监督和无监督学习的优点,通过引入少量标注数据来优化模型。例如,达摩院提出的半监督预训练对话模型SPACE 1.0,在经典对话数据集上取得了显著效果。
4. 多模态预训练
随着多模态任务的兴起,多模态预训练范式逐渐成为研究热点。例如,MiCo范式通过引入视觉、文本等多模态数据,实现了跨模态任务的高效学习。
预训练范式的优缺点
优点:
- 通用性强:预训练模型能够捕捉到丰富的特征表示,从而在多种任务上表现出色。
- 效率高:通过预训练阶段的学习,模型可以在下游任务中减少标注数据的需求。
- 可扩展性:预训练模型可以通过简单的微调适应不同的任务场景。
缺点:
- 计算成本高:大规模数据的预训练需要巨大的计算资源和时间成本。
- 知识共享不足:由于不同任务之间的知识可能存在差异,预训练模型在某些任务上的表现可能受限。
- 数据需求大:预训练需要大量的无标注数据支持,这在某些领域可能难以获取。
预训练范式的未来发展方向
随着人工智能技术的不断进步,预训练范式也在不断发展。未来的研究方向包括:
- 更高效的预训练方法:如何在有限的计算资源下实现高效的预训练。
- 跨模态融合:如何更好地结合不同模态的数据,提升多模态任务的表现。
- 少样本学习:如何在少量标注数据的情况下优化预训练模型。
- 知识注入:如何将领域知识有效地注入到预训练模型中,提升特定任务的效果。
预训练范式已经成为人工智能领域的重要基石,其广泛应用不仅推动了自然语言处理和计算机视觉的发展,还为其他领域的研究提供了新的思路和方法。未来,随着技术的不断进步,预训练范式将在更多领域展现其潜力。