隐狄利克雷分配(Latent Dirichlet Allocation, LDA)是一种广泛应用于自然语言处理和信息检索领域的主题模型,用于从文档集合中识别潜在的主题。LDA是一种无监督学习技术,能够从大量文本数据中自动发现隐藏的主题结构,无需标注数据。
核心概念与原理
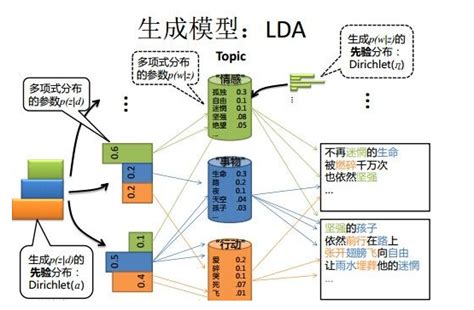
LDA是一种生成式模型,假设文档是由多个主题的混合生成的,每个主题由一组特定的词汇构成。具体来说,LDA模型认为每篇文档由多个主题组成,每个主题由一组特定的词汇构成。模型通过迭代算法学习主题和词汇的分布,从而实现主题的识别。
LDA的核心思想是将文档表示为潜在主题的随机混合,并对每个主题进行单词分布特征化。LDA通过估计词语与主题的后验分布,确定文档最可能的主题及主题相关的词语。
模型结构与生成过程
LDA模型包含三个层次结构:
- 文档层(Document Level) :每篇文档由多个主题组成,每个主题的权重由Dirichlet分布生成。
- 主题层(Topic Level) :每个主题由一组特定的词汇构成,词汇的分布由多项式分布生成。
- 词汇层(Word Level) :每个单词由主题生成,从对应主题的词汇分布中抽取。
LDA的生成过程包括:为每个文档分配主题权重,为每个单词分配主题,并从对应主题的词汇分布中抽取单词。
无监督学习与参数估计
LDA是一种无监督学习算法,无需标注数据,仅需文档集和指定主题数K。LDA通过变分推断或吉布斯采样等方法进行参数估计,以最大化观测数据(文档)的概率。由于后验分布难以用闭合形式表示,因此需要使用近似推断方法,如变分推断或吉布斯采样。
应用领域
LDA广泛应用于多个领域,包括:
优势与局限性
LDA的优势包括:
- 无监督学习,无需标注数据;
- 能够发现文档中的隐藏主题,降低文本数据的维度;
- 生成模型方法,能够捕捉语义相似性。
然而,LDA也存在一些局限性:
- 主题数量选择困难;
- 仅考虑词袋模型,忽略词语顺序和语法结构;
- 计算成本较高,生成主题可能缺乏语义。
总结
隐狄利克雷分配(LDA)是一种强大的主题模型,能够从文档集合中自动发现潜在的主题结构,广泛应用于自然语言处理、信息检索和文本分析等领域。尽管存在一些局限性,但其在无监督学习和主题建模方面具有显著优势
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!