掩码语言模型(Masked Language Model,MLM)是一种在自然语言处理(NLP)领域广泛应用的深度学习技术,主要用于训练基于Transformer架构的语言模型。其核心思想是通过随机遮蔽输入文本中的一部分单词,并要求模型预测这些被遮蔽的单词,从而学习语言的深层表示和上下文关系。
1. 基本概念与工作原理
掩码语言模型通过以下步骤实现:
- 输入处理:将原始文本转换为模型可处理的格式,包括分词和编码。例如,在BERT中,输入句子中的某些单词会被随机替换为一个特殊标记[MASK],而其余部分保持不变。
- 遮蔽操作:在训练过程中,输入文本中约15%的单词会被随机遮蔽,这些单词被替换为[MASK]标记。
- 预测任务:模型的任务是根据上下文信息预测被遮蔽的单词。例如,对于句子“The [MASK] five feet”,模型需要预测被遮蔽的单词“the”。
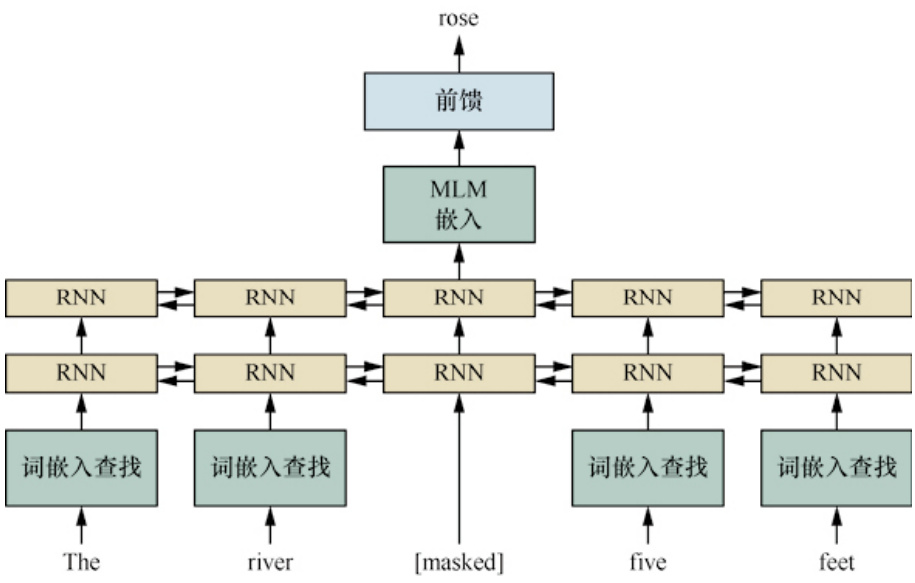
- 双向理解:与传统的单向语言模型不同,MLM利用Transformer的双向编码器结构,可以同时考虑左右两侧的上下文信息,从而更好地理解单词在句子中的语义和语法关系。
2. 技术特点
- 动态掩蔽:MLM采用动态掩蔽策略,即每次训练时随机选择不同的单词进行遮蔽,这使得模型能够学习到更多样化的语言特征。
- 上下文感知能力:通过预测被遮蔽的单词,模型能够捕捉到句子中单词之间的复杂关系,包括语义和语法结构。
- 自监督学习:MLM是一种自监督学习方法,不需要显式的标注数据,而是通过输入文本本身作为监督信号进行训练。
3. 应用场景
掩码语言模型在多个NLP任务中表现出色,包括但不限于:
- 文本分类:通过微调预训练的MLM模型,可以快速适应特定领域的文本分类任务。
- 命名实体识别:MLM能够捕捉到实体与其上下文的关系,从而提高命名实体识别的准确性。
- 情感分析:MLM通过理解句子的整体语义,能够更准确地判断文本的情感倾向。
- 问答系统:MLM可以用于构建问答系统,通过预测问题中的缺失部分来生成答案。
4. 优势与局限性
优势:
- 双向理解:MLM能够同时考虑左右两侧的上下文信息,从而更好地理解句子的深层含义。
- 通用性强:预训练的MLM模型可以作为许多下游任务的起点,减少对大量标注数据的需求。
- 性能优越:在多种NLP任务中,MLM模型通常能够取得较高的性能。
局限性:
- 计算成本高:由于需要处理大量的遮蔽样本,MLM的训练计算成本较高。
- 遮蔽比例影响性能:研究表明,当遮蔽比例过高时(如超过50%),模型性能会下降。
5. 代表性模型
- BERT:BERT是最早采用MLM技术的模型之一,通过双向Transformer架构实现了对文本的深度理解。
- RoBERTa:RoBERTa在BERT的基础上进一步优化了遮蔽策略和训练流程,提升了模型性能。
- GPT系列:虽然GPT采用的是单向自回归模型,但其预测下一个词的任务也可以视为一种特殊的MLM形式。
6. 未来发展方向
随着NLP技术的发展,MLM的应用范围将进一步扩大。例如,在多模态任务中,MLM不仅限于文本数据,还可以结合图像、音频等其他模态的信息进行联合学习。此外,针对特定领域的MLM模型(如中医药领域)也在不断探索中。
掩码语言模型通过随机遮蔽输入文本中的部分单词并预测这些单词,不仅提升了模型对上下文的理解能力,还为多种NLP任务提供了强大的基础工具。然而,随着技术的进步,如何进一步优化MLM的计算效率和适应性仍是未来研究的重要方向。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!