语义相似度(Semantic Textual Similarity, STS)是自然语言处理(NLP)中的一个核心任务,旨在衡量两个文本片段在语义上的相似程度。它不仅用于评估两个句子或文本之间的语义等价性,还广泛应用于信息检索、机器翻译、问答系统、文档聚类、自动客服、搜索引擎优化等任务。
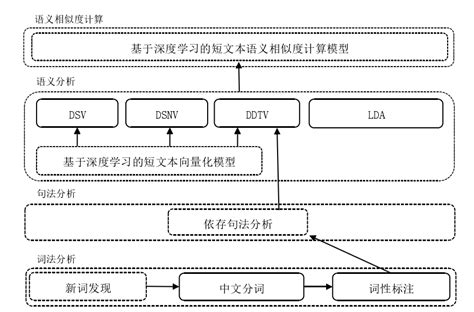
语义相似度(STS)的定义与特点
语义相似度(STS)的核心目标是衡量两个文本片段在语义上的相似程度。它通常通过一个连续的分数(如0到5的范围)来表示相似度,其中0表示完全不相似,5表示完全相似。与传统的二元分类(相似或不相似)不同,STS强调的是“分级相似性”(graded similarity),即两个文本之间的相似程度可以是部分相似、高度相似或完全相似。
STS 的任务特点
- 任务目标:STS 的核心任务是评估两个文本片段之间的语义相似性,通常通过模型输出一个连续的相似度分数。
- 与相关任务的区别:
- 文本蕴含(Textual Entailment, TE) :STS 与文本蕴含不同,后者是单向的(例如,“一辆车是一种交通工具”),而 STS 是双向的,即两个文本片段之间的相似性是对称的。
- 释义(Paraphrasing) :STS 与释义任务不同,后者通常是一个二元分类问题(是或不是),而 STS 是一个连续的评分任务。
- 挑战性:由于语言的复杂性、歧义性、句子长度和结构的多样性,STS 任务具有较高的挑战性。
STS 的应用与研究进展
- 应用领域:STS 广泛应用于信息检索、机器翻译、问答系统、自动摘要、文本聚类、抄袭检测等任务。
- 研究进展:近年来,基于深度学习的模型(如 BERT、T5、GPT 等)在 STS 任务中取得了显著进展,尤其是在大规模预训练模型和微调方法的应用上。
- 评估与基准:STS 任务通常通过共享任务(如SemEval STS) 进行评估,使用人类评分和机器评分的 Pearson 相关性进行评估。
语义相似度(STS)的挑战与未来方向
尽管 STS 任务在自然语言处理中具有重要意义,但其仍面临一些挑战,例如:
- 语言歧义与主观性:句子的语义相似性可能因上下文、文化背景或个人理解而异。
- 模型可解释性:如何提高模型的可解释性,使其决策过程更透明,是当前研究的一个重要方向。
- 跨语言与多模态扩展:如何扩展 STS 到跨语言、多模态(文本、图像、音频)等复杂场景,是未来研究的重要方向。
总结
语义相似度(STS)是自然语言处理中的一个核心任务,旨在衡量两个文本片段在语义上的相似程度。它不仅在理论研究中具有重要意义,也在实际应用中发挥着重要作用。随着深度学习和大规模预训练模型的发展,STS 任务正在不断进步,为自然语言处理和人工智能的发展提供了重要支持。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!