词错误率(Word Error Rate,简称 WER)是评估语音识别、机器翻译、光学字符识别等序列输出系统准确性的一种常用指标。它通过比较系统输出(假设文本)与人工标注的参考文本(真值)之间的差异,量化错误的比例。
1. 计算公式
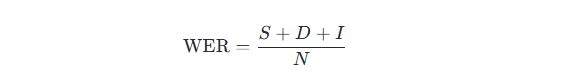
- S(Substitutions):将参考文本中的一个词错误地替换为另一个词的次数。
- D(Deletions):在系统输出中漏掉参考文本中的词的次数。
- I(Insertions):系统输出中多余的、在参考文本里不存在的词的次数。
- N:参考文本中词的总数(即真值词数)。
WER 实际上是 编辑距离(Levenshtein distance) 在词层面的表现形式。
2. 计算步骤
- 分词
将参考文本和系统输出分别切分成词序列(通常以空格或标点为分界)。 - 对齐
使用动态规划算法(如 Levenshtein)在两个词序列之间找到最小编辑路径。 - 统计错误
从对齐结果中统计 S、D、I 三类错误。 - 代入公式
将统计值代入上式得到 WER。
3. 示例
| 参考文本(Reference) | 系统输出(Hypothesis) | 错误类型 | 计数 |
|---|---|---|---|
| “今天 天气 很 好” | “今天 天气 好” | 删除 (D) | 1 |
| “我 喜欢 听 音乐” | “我 喜欢 听 歌曲” | 替换 (S) | 1 |
| “他 去 了 北京” | “他 去 了 北京 了” | 插入 (I) | 1 |
- N = 8(参考文本词数)
- S = 1, D = 1, I = 1
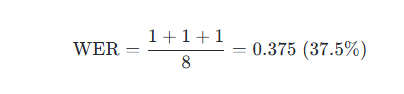
4. 适用场景
5. 优缺点
| 优点 | 缺点 |
|---|---|
| 直观、易于解释; 能够捕捉插入、删除、替换三类错误。 |
对长句子或结构变化敏感; 不考虑词序的语义重要性; 对同义词替换不作惩罚,可能导致“过高”错误率。 |
6. 常见改进
- 字符错误率(CER):在字符层面计算,适用于中文等无空格分词的语言。
- 词级别的加权 WER:对关键词赋予更高权重,以反映业务重要性。
- 使用语言模型进行对齐:在对齐阶段加入语言模型约束,降低因偶然对齐导致的误判。
7. 小结
词错误率(WER)是通过 插入、删除、替换 三类编辑操作相对于参考词数的比例来衡量系统输出质量的指标。它在语音识别等序列生成任务中被广泛采用,能够提供一个直观的错误比例,但也需要结合其他评估手段(如语义相似度、BLEU、CER)来获得更全面的性能评估。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!