视觉SLAM(Simultaneous Localization and Mapping,即时定位与地图构建)是一种通过视觉传感器(如相机)获取环境信息,同时进行实时定位和地图构建的技术。其核心目标是利用图像数据实现机器人或移动设备在未知环境中的定位与地图构建。
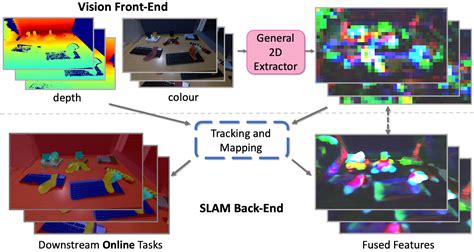
视觉SLAM的基本原理与工作流程
视觉SLAM的核心在于通过摄像头获取的图像数据,估计相机的运动轨迹和周围环境的三维结构。其工作流程通常包括以下几个步骤:
- 传感器数据读取:通过摄像头获取图像数据,作为输入信息。
- 视觉里程计(VO) :估算相邻图像之间的相机运动和局部地图的构建。
- 后端优化:对视觉里程计的结果进行优化,以提高定位精度和地图一致性。
- 回环检测:判断机器人是否曾到达过先前位置,提供闭环信息以消除累积误差。
- 建图:根据估计的轨迹和地图信息,构建环境的三维地图。
视觉SLAM的传感器与分类
视觉SLAM主要依赖于视觉传感器,常见的传感器类型包括:
- 单目相机:成本低,但无法直接获取深度信息,存在尺度不确定性问题。
- 双目相机:通过视差计算深度信息,计算量较大。
- RGB-D相机:直接测量像素距离,提供更丰富的信息,但存在测量范围窄、噪声大等问题。
- 事件相机:具有高动态范围和低功耗,适用于高速和高动态场景。
视觉SLAM的应用领域
视觉SLAM广泛应用于多个领域,包括:
视觉SLAM的挑战与发展趋势
尽管视觉SLAM在成本和灵活性方面具有优势,但也面临一些挑战,如光照变化、动态障碍物、光照变化等问题。未来,视觉SLAM与激光SLAM的融合将是趋势,以结合两者的优势,提高定位精度和地图构建能力。
总结
视觉SLAM是一种基于视觉传感器的SLAM技术,通过图像数据实现定位与地图构建,广泛应用于机器人、自动驾驶、AR/VR等领域。尽管存在一些挑战,但随着技术的发展,其应用前景广阔
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!