自动混合精度(Automatic Mixed Precision, AMP)是一种在深度学习训练中结合不同精度浮点数(如FP32和FP16)以提高训练效率和性能的技术。它通过在训练过程中自动选择使用单精度(FP32)和半精度(FP16)计算,以减少内存占用并加速训练过程。
核心原理与优势
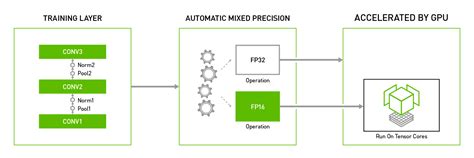
- 混合精度计算:AMP通过结合FP32(单精度)和FP16(半精度)浮点数,利用FP16计算速度快、内存占用少的优势,同时在关键步骤(如梯度计算和权重更新)中使用FP32以保持精度。
- 性能提升:FP16的计算速度和内存效率远高于FP32,尤其在GPU上,如NVIDIA的Tensor Core支持下,AMP可显著提升训练速度(2-3倍)。
- 内存优化:FP16的内存占用仅为FP32的一半,显著减少显存使用,尤其在大规模模型训练中具有重要价值。
- 精度与效率平衡:通过梯度缩放(Gradient Scaling)和损失缩放(Loss Scaling)等技术,AMP在保持模型精度的同时,有效解决FP16可能带来的精度损失问题。
实现与应用
- 框架支持:AMP广泛应用于主流深度学习框架,如PyTorch、TensorFlow、PaddlePaddle等,提供API和工具支持混合精度训练。
- 实现方式:AMP通常通过自动混合精度(Autocast)和梯度缩放(GradScaler)实现,用户可通过API或配置文件启用混合精度训练。
- 应用场景:AMP广泛应用于目标检测、强化学习、自然语言处理等领域,显著提升训练效率和模型性能。
挑战与注意事项
- 精度与稳定性:FP16可能引入数值溢出和舍入误差,需通过梯度缩放和损失缩放等技术进行补偿。
- 硬件依赖:AMP的性能提升依赖于硬件支持(如NVIDIA GPU的Tensor Core),不同硬件平台可能影响效果。
总结
自动混合精度(AMP)是一种通过结合FP32和FP16计算,提升深度学习训练效率和性能的技术。它通过混合精度计算、梯度缩放和硬件优化,显著减少内存占用、加速训练过程,同时保持模型精度,是现代深度学习训练中的重要技术手段
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!