混合精度训练(Mixed Precision Training)是一种在深度学习训练中广泛应用的技术,旨在通过结合不同精度的数据类型(如FP16和FP32)来优化训练过程,以提高计算效率、减少内存占用并保持模型精度。
核心原理与目标
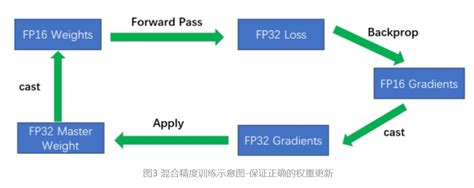
混合精度训练的核心思想是结合使用低精度(如FP16)和高精度(如FP32)的数据类型进行计算。FP16(半精度浮点数)计算速度快、内存占用少,但精度较低;而FP32(单精度浮点数)精度高,但计算和内存开销较大。通过混合使用这两种精度,可以在保持模型精度的同时,显著提升训练速度和降低内存使用。
关键技术与实现方法
- 精度混合:在训练过程中,模型的计算和存储操作可以使用不同的精度。例如,激活值和梯度可以使用FP16进行计算,而权重和主参数则使用FP32存储,以避免精度损失。
- 损失缩放(Loss Scaling) :由于FP16的动态范围较小,可能导致梯度下溢。为解决这一问题,引入损失缩放技术,通过在反向传播前放大损失值,再在更新权重时进行缩放,以防止梯度溢出。
- 自动混合精度(Automatic Mixed Precision, AMP) :现代深度学习框架(如PyTorch、TensorFlow)提供了自动混合精度训练工具,简化了混合精度训练的实现过程,用户只需配置相关参数即可启用。
优势与应用场景
混合精度训练的主要优势包括:
- 提高训练速度:通过使用FP16加速计算,显著减少训练时间(例如,训练速度可提升2-3倍)。
- 减少内存占用:FP16的内存占用仅为FP32的一半,有助于训练更大规模的模型。
- 提高硬件利用率:尤其在支持FP16计算的硬件(如NVIDIA Tensor Core)上,混合精度训练效果更显著。
挑战与解决方案
尽管混合精度训练具有诸多优势,但也面临一些挑战:
- 数值稳定性问题:FP16的精度较低可能导致梯度下溢或溢出,需通过损失缩放等技术解决。
- 硬件依赖性:某些硬件(如不支持FP16的GPU)可能无法充分利用混合精度训练的优势。
应用领域
混合精度训练广泛应用于大规模模型训练(如BERT、GPT等)、计算机视觉、自然语言处理等领域,尤其在训练大型模型时效果显著。
总结
混合精度训练是一种通过结合不同精度数据类型来优化深度学习训练的技术,能够在保持模型精度的同时,显著提升训练效率和降低资源消耗。随着深度学习模型规模的不断增长,混合精度训练已成为现代深度学习训练的重要技术之一
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!