梯度缩放(Gradient Scaling)是一种在深度学习中用于优化模型训练的技术,其核心思想是通过调整梯度的数值范围来解决训练过程中可能出现的梯度下溢或上溢问题,从而提高模型训练的稳定性和效率。
1. 梯度缩放的基本原理
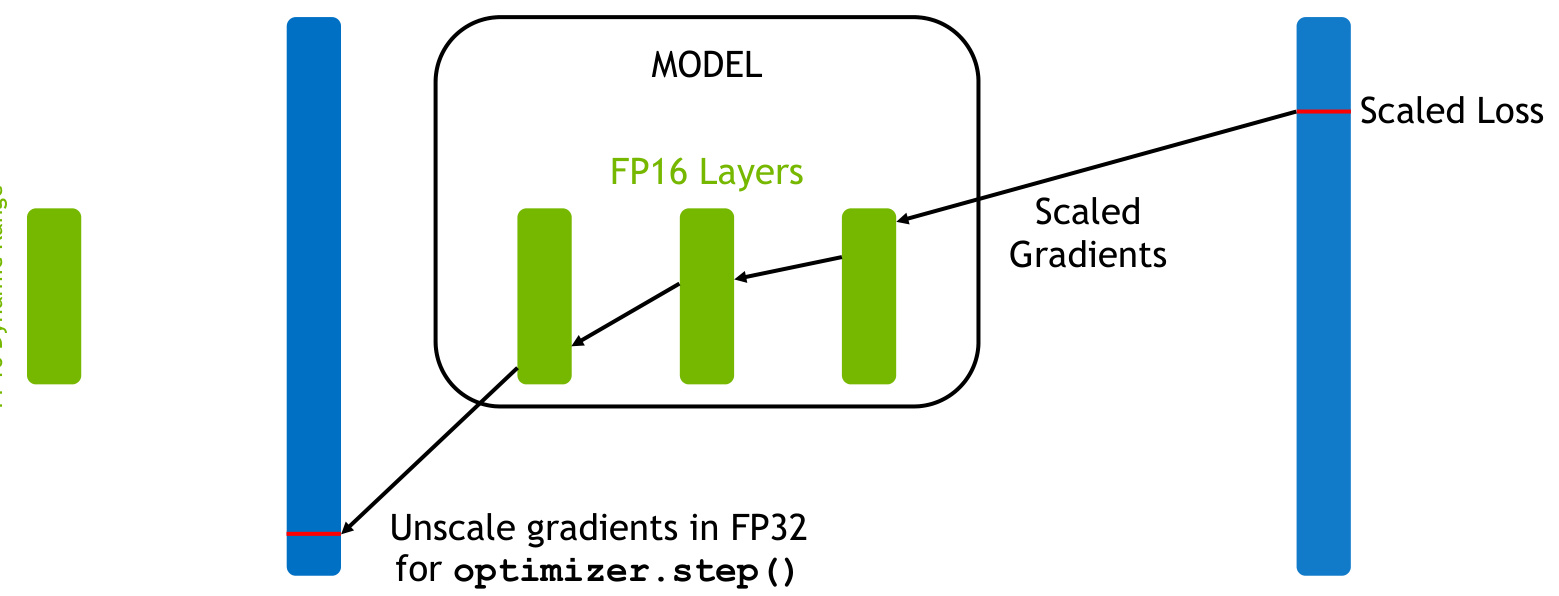
梯度缩放的核心思想是通过动态调整梯度的数值范围,以避免在使用低精度浮点数(如FP16)进行训练时可能出现的梯度下溢问题。当使用低精度浮点数时,由于其表示范围较窄,梯度值可能会变得非常小,导致梯度下溢(即梯度值变为零),从而影响模型的训练效果。
在梯度缩放中,通常会在反向传播前将损失值乘以一个缩放因子,使得计算出的梯度具有足够的数值范围,避免下溢。在更新参数前,再将梯度相应缩小,以确保学习速率不受影响。
2. 梯度缩放的实现方式
在PyTorch等深度学习框架中,梯度缩放通常通过torch.cuda.amp.Gr adScaler实现。该工具可以自动调整缩放因子,根据梯度的大小动态调整缩放比例,以避免梯度下溢或上溢。
3. 梯度缩放的应用场景
梯度缩放广泛应用于混合精度训练(Mixed Precision Training)中,特别是在使用低精度浮点数(如FP16)进行训练时,梯度缩放可以显著提高训练效率和模型性能。此外,梯度缩放在图像识别、自然语言处理、强化学习等领域也有广泛应用。
4. 梯度缩放的优势
- 提高训练稳定性:通过避免梯度下溢或上溢,梯度缩放可以提高模型训练的稳定性,防止模型训练过程中出现梯度消失或爆炸问题。
- 提高训练效率:梯度缩放可以加速模型训练过程,减少计算资源的消耗,特别是在大规模模型训练中效果显著。
- 适应不同硬件环境:梯度缩放可以适应不同硬件环境下的训练需求,提高模型的适应性和灵活性。
5. 梯度缩放的实现示例
在PyTorch中,梯度缩放的实现通常包括以下步骤:
- 创建
GradScaler实例。 - 在反向传播前调用
scaler.sc ale(loss).backward()。 - 在更新参数前调用
scaler.st ep(optimizer)。 - 在更新参数后调用
scaler.update()。
6. 梯度缩放与其他技术的比较
梯度缩放与梯度裁剪(Gradient Clipping)和梯度累积(Gradient Accumulation)等技术有相似之处,但侧重点不同。梯度缩放更侧重于通过动态调整梯度的数值范围来解决梯度下溢或上溢问题,而梯度裁剪则通过限制梯度的大小来防止梯度爆炸。
7. 梯度缩放的挑战与未来发展方向
尽管梯度缩放在深度学习中广泛应用,但仍面临一些挑战,如如何在不同硬件环境下优化梯度缩放的性能,以及如何进一步提高模型训练的效率和稳定性。
总结
梯度缩放是一种在深度学习中用于优化模型训练的重要技术,通过动态调整梯度的数值范围,解决梯度下溢或上溢问题,提高模型训练的稳定性和效率。其在混合精度训练、图像识别、自然语言处理等领域有广泛应用