强化学习是一种通过智能体与环境交互来学习最优行为策略的机器学习方法,其核心目标是最大化累积奖励。与监督学习和无监督学习不同,强化学习依赖于环境的即时反馈(奖励信号),而非标记数据。在强化学习中,状态、动作、奖励和策略共同构成了一个完整的框架,其中策略定义了智能体在给定状态下选择行为的方式。
常见的强化学习算法包括:
- PPO(Proximal Policy Optimization)算法
PPO是一种基于策略梯度的强化学习算法,属于策略优化方法。它通过限制新旧策略之间的差异来稳定训练过程,避免因策略更新过大而导致性能下降。PPO的核心思想是引入“近端策略优化”机制,通过约束梯度更新幅度来提高样本效率和稳定性。- 优点:PPO具有较高的样本效率和稳定性,适用于高维观测和连续动作空间的任务。此外,它对超参数不敏感,易于实现和调试。
- 应用场景:PPO被广泛应用于机器人控制、游戏(如Atari游戏)以及自动驾驶等领域。
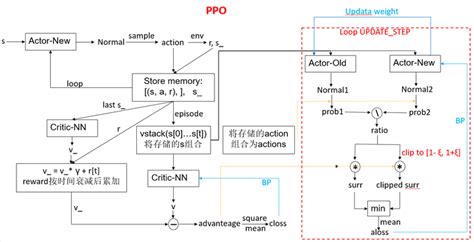
- GRPO(Group Relative Policy Optimization)算法
GRPO是PPO的一种改进版本,旨在解决传统PPO在大规模语言模型(LLM)训练中的局限性。GRPO通过组内相对归一化的方式计算奖励,并引入了Kullback-Leibler(KL)散度约束,以确保策略更新不会过于激进。- 核心特点:
- 组内相对归一化:对每个输入提示生成多个输出,计算组内相对奖励,从而减少对单一奖励模型的依赖。
- KL散度约束:通过限制策略更新幅度,避免过度调整。
- 优势:GRPO在计算效率和训练稳定性方面优于PPO,特别适合需要复杂推理和长序列任务的场景,如数学推理和代码生成。
- 应用场景:GRPO已被成功应用于DeepSeek-R1模型的训练,用于提升大型语言模型的推理能力。

- 其他常见强化学习算法
- Q-learning 和 SARSA:基于值函数的算法,通过学习状态-动作对的价值函数来优化策略。
- A2C 和 DDPG:基于Actor-Critic框架的算法,结合了策略梯度和值函数方法,适用于连续动作空间的任务。
- TRPO 和 P3O:基于信任域优化的算法,通过限制策略更新幅度来提高稳定性。
总结
强化学习算法种类繁多,每种算法都有其独特的适用场景和优缺点。PPO因其高效性和稳定性成为许多任务的首选算法,而GRPO则进一步优化了PPO在大规模模型训练中的表现。未来的研究可能会继续探索更高效的强化学习算法,以应对更加复杂的任务需求
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!