对抗攻击(Adversarial Attack)是机器学习领域中一个重要的安全问题,尤其在深度学习模型中表现得尤为突出。它指的是通过向输入数据中添加微小的扰动,使得模型产生错误的预测结果。这些扰动通常非常小,以至于人类难以察觉,但足以导致模型输出错误。
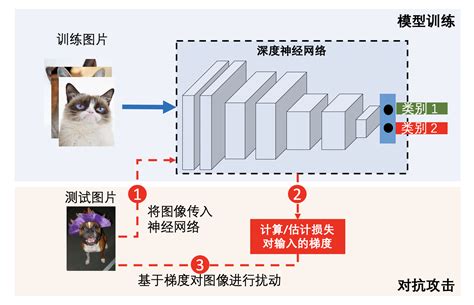
对抗攻击的目的是利用模型的漏洞和缺陷,通过优化方法自动寻找特定的输入数据,使得模型产生错误或不符合预期的输出。攻击者可以根据模型结构生成对抗样本,分为白盒攻击(攻击者知道模型参数)和黑盒攻击(攻击者不了解模型参数)。攻击方式包括无目标攻击(仅使模型误判)和有目标攻击(使模型误判为特定类别)。
对抗攻击的原理在于,通过对输入数据添加微小扰动,人类难以察觉这些扰动,但它们会导致模型产生完全错误的预测。对抗攻击揭示了深度学习模型对数据中某些脆弱特征的过度依赖,表明模型并非如预期般鲁棒。
对抗攻击的攻击方法包括FGSM(Fast Gradient Sign Method)、JSMA(Jacobian-based Saliency Map Attack)、DeepFool等。防御策略包括对抗训练、防御性蒸馏、特征压缩等。对抗训练是通过在原始样本上添加微小扰动形成对抗样本进行再训练,以增强神经网络模型的鲁棒性。
对抗攻击的应用广泛,涵盖图像分类、语义分割、人脸识别、自动驾驶、自然语言处理等领域。对抗攻击对安全关键系统(如自动驾驶系统)构成重大威胁,因为错误的预测可能导致致命事故。
对抗攻击的研究方向包括攻击原理、攻击方法、防御策略及实际应用,未来研究方向包括更高效的攻击方法、更有效的防御策略、特定场景下的攻击防御研究,以及提升模型泛化能力的防御手段
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!