字符错误率(CER,Character Error Rate)是一种用于衡量文本识别系统(如自动语音识别 ASR、光学字符识别 OCR、机器翻译等)在字符层面准确性的指标。它通过比较系统输出文本与人工标注的参考文本,统计两者之间的编辑距离(Levenshtein distance),进而得到错误字符占总字符数的比例。
1. 计算公式
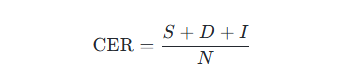
- S(Substitutions):需要替换的字符数
- D(Deletions):需要删除的字符数
- I(Insertions):需要插入的字符数
- N:参考文本(ground‑truth)中的字符总数
该公式直接体现了“把系统输出变成参考文本所需的最少字符操作数占参考字符数的比例”。当所有字符均正确时,CER = 0;数值越大表示错误越多。
2. 计算步骤(概览)
- 准备文本:获取参考文本和系统预测文本,统一字符编码、大小写、标点等预处理。
- 计算编辑距离:使用 Levenshtein‑distance 算法(动态规划实现)得到 S、D、I 三类错误的数量。
- 代入公式:将 S、D、I 与 N 带入上式,得到 CER(通常以百分比或小数形式呈现)。
常用的开源实现包括 Python 的 jiwer、torchmetrics.char_error_rate、python-Levenshtein 等,它们内部已封装了上述步骤。
3. 应用场景
| 场景 | 作用 |
|---|---|
| 自动语音识别(ASR) | 评估语音转文字系统在中文、英文等语言的字符级准确性,尤其适用于字符数多、词长变化大的语言 |
| 光学字符识别(OCR) | 衡量扫描文档、手写文字等转化为数字文本的错误率,低 CER 能显著提升后续检索和编辑效率 |
| 机器翻译 / 文本生成 | 在对细粒度(如医学、法律文档)要求极高的场景下,CER 能捕捉词级指标(WER)忽略的细微错误 |
| 车牌识别、验证码识别 | 直接关系到系统的可用性,CER 越低意味着识别错误导致的业务风险越小 |
4. 与词错误率(WER)的区别
- 粒度不同:WER 按词(word)统计错误,CER 按字符(character)统计。对中文、日文等无明显分词的语言,CER 更直观。
- 敏感度:CER 能捕捉单字符的拼写错误或漏字,而 WER 可能把整个词算作一次错误,导致误差被低估。
- 数值范围:两者均在 0 ~ 1(或 0 % ~ 100 %)之间,但在高错误率时 CER 往往更接近上限,因为插入字符会直接累加到分子。
5. 解释意义与使用建议
- 数值越低越好:CER = 0 表示完美匹配;实际系统常在 0.5 % ~ 5 % 之间波动,具体取决于任务难度和数据质量。
- 对比基准:在同一数据集上比较不同模型时,CER 提供了统一的量化标准。
- 结合其他指标:建议同时报告 CER、WER 以及字符级准确率(CAR)等,以获得更全面的评估。
6. 常用实现示例(Python)
from jiwer import wer, cer
reference = "今天天气很好,我想去公园散步。"
hypothesis = "今天天气很棒,我想去公园散步。"
cer_value = cer(reference, hypothesis) # 计算字符错误率
print(f"CER = {cer_value:.4f}") # 示例输出:CER = 0.0250
上述代码利用 jiwer 库直接返回字符错误率,内部已完成 Levenshtein 距离的计算。
总结:字符错误率(CER)是衡量文本识别系统在字符层面错误比例的核心指标。它通过统计替换、删除、插入三类错误相对于参考字符总数的比例,提供了对系统细粒度准确性的直观量化。CER 在 ASR、OCR、机器翻译等多种场景中被广泛采用,是评估和优化文本处理模型不可或缺的工具。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!