奖励模型(Reward Model,RM)概述
1. 什么是奖励模型
奖励模型是一类用于评估智能体(如语言模型、机器人或游戏代理)行为质量的模型。它接受智能体的输出(文本、动作序列等)并输出一个标量分数——奖励值,该分数越高表示行为越符合预设目标或人类偏好。在强化学习(RL)框架中,奖励模型相当于“裁判”,为智能体提供正向或负向的学习信号,从而引导策略的改进。
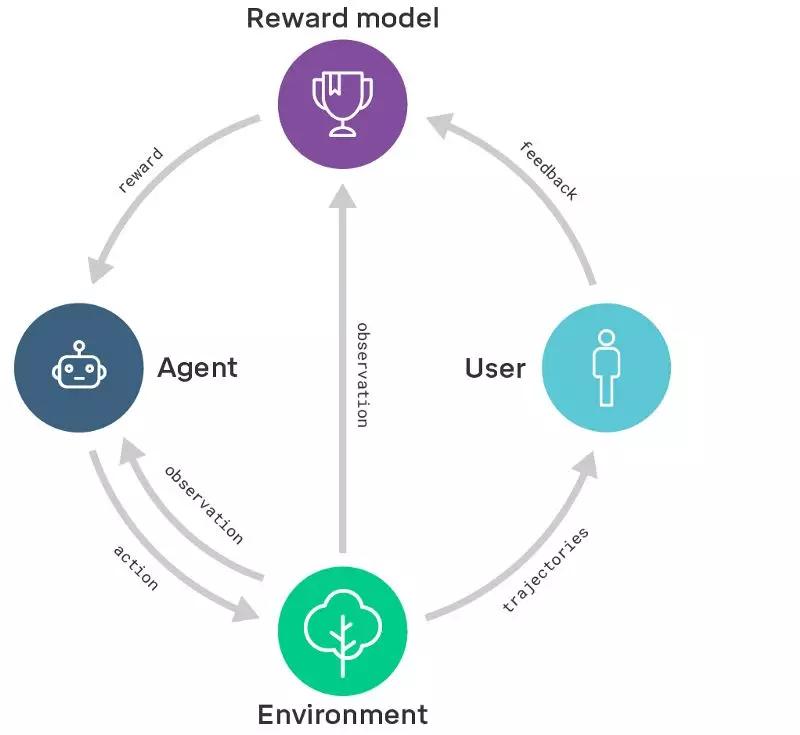
2. 核心原理
- 输入:智能体在特定情境下产生的行为或响应(如一段对话、一个动作序列)。
- 输出:一个实数(或概率),表示该行为的“好坏”。
- 作用:在训练阶段,奖励模型的分数被用作强化学习的奖励信号,帮助智能体最大化累计奖励;在推理阶段,它可以直接用于对多个候选答案进行排序或筛选。
3. 训练方法
- 收集人类偏好数据
- 让人工标注者对同一输入的多个模型输出进行比较、排序或打分,得到“好答案”和“差答案”。
- 构建对比学习任务
- 常用 Pairwise Ranking Loss(如 Bradley‑Terry 模型)或 对数似然 方式,使奖励模型学习在好答案上给出更高分数。
- 模型结构
- 多数实现基于 Transformer 或 BERT 等预训练语言模型,在其顶部加一个 分类头(单层全连接)输出标量分数。
- 交叉验证与迭代
- 通过多轮人类反馈(RLHF)不断更新奖励模型,使其更贴合真实偏好。
4. 常见类型
| 类型 | 关注对象 | 典型应用 |
|---|---|---|
| Outcome Reward Model (ORM) | 整体输出的质量(答案正确性、流畅度等) | LLM 对话对齐、文本生成 |
| Process Reward Model (PRM) | 生成过程中的每一步(推理路径、动作序列) | 多步推理、机器人动作规划 |
| 自生成批评(Self‑Critique RM) | 让模型自行评估并改进自己的输出 | 提升长时推理能力 |
5. 在 RLHF(Reinforcement Learning with Human Feedback)中的角色
- 人类反馈的桥梁:先用人类偏好训练奖励模型,再用该模型提供的奖励信号对主模型进行强化学习(如 PPO),实现“让模型更符合人类期望”。
- 优化目标:奖励模型定义了 RL 的奖励函数,使得优化过程不必直接依赖稀疏或难以手工设计的奖励。
- 实际流程:
- 预训练模型 → 生成候选答案 → 人类标注 → 训练奖励模型 → 用奖励模型进行 RL 微调 → 产出对齐模型。
6. 应用场景
- 大语言模型对齐:ChatGPT、Claude 等通过奖励模型实现更安全、友好的对话。
- 机器人控制:让机器人在模拟或真实环境中通过奖励模型学习抓取、行走等技能。
- 游戏 AI:在围棋、星际争霸等复杂游戏中,用奖励模型评估局面并指导策略搜索。
- 自动驾驶:奖励模型评估驾驶行为的安全性与舒适度(虽受政策限制,此处仅作技术说明)。
7. 面临的挑战与发展方向
- 奖励滥用(Reward Hacking):智能体可能学会“骗取”高分而不真正完成任务,需要更稳健的奖励设计。
- 偏见与公平:奖励模型学习自人类标注,可能继承标注者的偏见,需要多元化数据与去偏技术。
- 可解释性:如何解释奖励模型给出的分数仍是研究热点。
- 跨模态奖励:将视觉、语言等多模态信息统一到同一奖励模型中,以支持更复杂的任务。
8. 小结
奖励模型是强化学习体系中的关键评估组件,尤其在 RLHF 中承担将人类偏好转化为可量化奖励的桥梁作用。它通过对行为打分,引导智能体不断优化策略,使得 AI 系统能够在复杂、难以手工定义奖励的任务中实现高质量、符合人类期望的表现。随着模型规模和多模态技术的提升,奖励模型的设计与训练方法也在持续演进,未来将在更广泛的实际场景中发挥核心作用。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!