什么是大语言模型(LLM)
大语言模型(Large Language Model, LLM)是一种基于深度学习的人工智能模型,旨在理解和生成人类语言。它通过在大量文本数据上进行训练,学习语言的模式和结构,从而能够生成自然语言文本或理解语言含义。
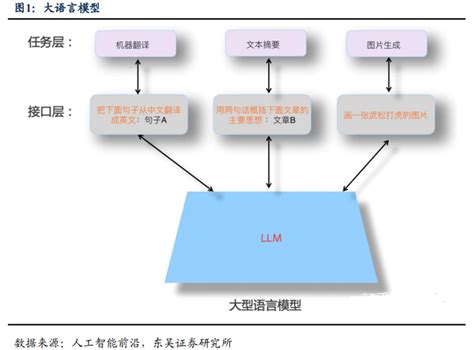
核心特征与工作原理
- 大规模参数与训练数据
LLM 通常包含数十亿甚至数千亿参数,这些参数是在大量文本数据上训练的。这些数据来源广泛,包括网络爬虫、维基百科、GitHub 代码库等。模型通过自监督学习(unsupervised learning)进行训练,即在未标记的数据上学习语言模式。 - 生成与理解能力
LLM 能够生成连贯且上下文相关的文本,例如回答问题、翻译、创作内容等。它们通过预测下一个词或生成文本来实现这一目标。 - 架构与技术基础
LLM 通常基于 Transformer 架构,这是一种高效的神经网络架构,能够并行处理数据,提高训练效率。此外,LLM 通过预训练(pre-training)和微调(fine-tuning)来优化模型性能。
应用领域
LLM 在多个领域有广泛应用,包括但不限于:
挑战与局限性
尽管 LLM 具有强大的能力,但也面临一些挑战:
- 数据偏见与伦理问题:模型可能继承训练数据中的偏见,导致输出不公正或不准确。
- 可解释性与透明度:LLM 的决策过程难以解释,缺乏透明度。
- 计算资源需求:训练和运行 LLM 需要巨大的计算资源和能源消耗。
未来发展
随着技术的进步,LLM 正朝着更智能、个性化和可解释的方向发展。多模态学习(multimodal learning)和跨领域应用成为趋势,未来可能进一步推动人工智能的发展。
总结
大语言模型(LLM)是人工智能领域的重要突破,通过大规模数据和深度学习技术,实现了对人类语言的深刻理解和生成。尽管面临挑战,但其在多个领域的广泛应用和持续发展,使其成为推动人工智能进步的重要力量
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!