前向选择(Forward Selection)是一种在统计建模和机器学习中广泛使用的特征选择方法,其核心思想是从一个空模型开始,逐步添加对模型预测能力有显著贡献的特征,直到满足某个停止条件。
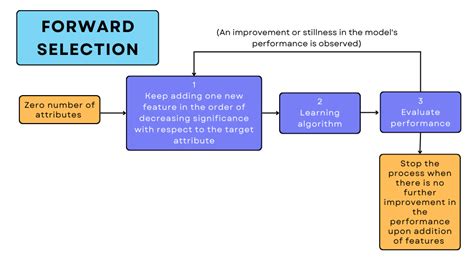
前向选择的基本原理
前向选择是一种逐步回归方法,它从一个空模型开始,逐步添加自变量(或特征),每次添加一个变量,直到满足某个停止准则。在每一步,通过统计检验(如p值、AIC、BIC等)或模型性能指标(如R²、调整R²)评估候选变量的重要性,并选择对因变量有显著影响的变量进行添加。
前向选择的步骤
- 初始化:从一个空模型开始,即没有任何自变量的模型。
- 逐步添加变量:在每一步中,从剩余的候选变量中选择一个对模型性能提升最大的变量(如p值最小、AIC最小或模型性能最佳)。
- 重新评估模型:在添加每个变量后,重新评估模型的性能,并检查是否满足停止条件(如达到预设的特征数量、模型性能不再提升或p值不再显著)。
- 停止条件:当无法再添加变量或模型性能不再提升时,停止添加过程。
前向选择的优点
- 操作简单:前向选择的实现相对简单,易于理解和实现。
- 降低模型复杂度:通过逐步添加变量,可以避免模型过拟合,提高模型的可解释性。
- 适用于高维数据:在特征数量较多的情况下,前向选择能够有效筛选出最相关的特征,提高模型的预测能力。
前向选择的缺点
- 可能忽略交互作用:前向选择只考虑单个变量的影响,可能忽略变量之间的交互作用,导致模型性能下降。
- 可能忽略重要变量:由于前向选择是逐步添加变量,可能会忽略某些重要但不显著的变量。
- 计算成本较高:在每一步中都需要重新评估模型性能,计算成本较高。
前向选择的应用场景
前向选择广泛应用于统计建模、机器学习和数据分析领域,特别是在回归分析、特征选择和模型优化中。例如,在经济学、医疗、营销等领域,前向选择被用于构建预测模型,提高模型的准确性和可解释性。
实现方法
前向选择可以通过多种编程语言和工具实现,例如Python中的scikit-learn库提供了前向选择的实现方法。此外,许多统计软件(如R、Python)也提供了前向选择的实现工具。
总结
前向选择是一种逐步添加变量的特征选择方法,通过逐步添加对模型性能有显著贡献的变量,构建最优的预测模型。尽管前向选择存在一些缺点,但其在统计建模和机器学习中具有重要的应用价值
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!