1. 背景与动机
- 上下文学习(In‑Context Learning, ICL) 是大语言模型在不给模型参数更新的前提下,仅通过在提示中提供少量示例来完成新任务的能力。传统的自回归 ICL(AR‑ICL)对示例的排列顺序极为敏感,稍微改变上下文顺序就会导致显著的性能波动。
- 为了克服这一缺陷,研究者提出了 不变 ICL(Invariant ICL)系列方法,试图实现 排列不变性。然而,已有的不变 ICL 往往在 信息泄漏(上下文示例的标签信息在训练阶段被模型直接看到)或 上下文相互依赖(示例之间的交互被削弱)上做出妥协,导致整体性能不如标准 AR‑ICL。
2. InvICL 的核心目标
InvICL 通过 三大原则 同时满足:
- 排列不变性:模型对上下文示例的顺序不敏感。
- 信息不泄漏:在预测阶段,模型不能直接看到目标示例的标签信息。
- 上下文相互依赖:上下文示例之间能够相互交流、共享信息,从而提升学习效果。
这三个目标在现有方法中难以兼得,InvICL 通过 留一法(Leave‑One‑Out, LOO)注意力掩码 与 对称位置编码 的组合实现了统一的解决方案。
3. 方法细节
| 步骤 | 关键技术 | 作用 |
|---|---|---|
| (1) 预编码(Leave‑One‑Out) | 对每个上下文示例单独进行自注意力编码,掩码掉自身的标签信息 | 确保 信息不泄漏,每个示例只看到其他示例的内容 |
| (2) 交叉注意力聚合 | 使用 LOO 注意力掩码 将所有上下文嵌入聚合到目标示例上 | 实现 上下文相互依赖,模型能够利用全部上下文信息进行预测 |
| (3) 对称位置编码(Symmetric PE) | 采用对称的相对位置编码,使注意力权重对任意排列保持不变 | 保证 排列不变性,即使上下文顺序改变,注意力矩阵保持相同 |
| (4) 并行实现 | 将上述三步合并为一次前向传播,计算复杂度与前缀 ICL 同阶,仅略高于 AR‑ICL(约两倍) | 在保持效率的前提下实现上述三大目标 |
4. 理论分析
- 计算复杂度:对n条上下文示例,InvICL 需要
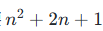 次注意力计算,与前缀 ICL 的
次注意力计算,与前缀 ICL 的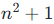 同阶,仅比 AR‑ICL 多约两倍,仍保持线性可扩展性。
同阶,仅比 AR‑ICL 多约两倍,仍保持线性可扩展性。 - 梯度下降等价性:从优化视角出发,InvICL 的前向传播可视为在隐式空间中执行一次 梯度下降 步骤,尤其在 线性回归 任务上能够逼近传统 GD 的收敛路径。这解释了其在少量示例下快速收敛的现象。
- 对称性与泛化:理论上,尊重输入的对称性(排列不变)能够提升模型的 归纳偏置,从而在 长度外推(即测试时上下文数量超过训练时)上表现更好。实验验证了 InvICL 在序列长度超出训练范围时仍保持优势。
5. 实验结果概览
- 合成任务(线性回归、稀疏回归、决策树等)
- InvICL 在收敛速度上显著快于 AR‑ICL,约在 50k 轮训练后即可达到低误差,而 AR‑ICL 需要 100k 轮以上。
- 在 长度外推 实验中,当测试序列长度从 40 扩展到 80、120 时,InvICL 的性能下降幅度最小,仍领先于 AR‑ICL 与 Prefix‑ICL。
- 真实世界基准(GPT‑2、GPT‑Neo、Pythia 等模型上的多任务集合)
- 在 7 项任务的 全域任务 设置中,InvICL 在 4 项任务上取得最高分;在 未见域(OOD)设置中,InvICL 在全部 7 项任务上均优于基线。
- 与其他不变 ICL 方法相比,InvICL 在 信息不泄漏 与 上下文相互依赖 两方面的改进,使其整体平均得分显著提升,几乎所有实验中均超过传统 AR‑ICL。
- 效率与资源
- 推理时间与 AR‑ICL 相近,内存开销约增加 14%(以 GPT‑2 Large 为例)。在实际部署场景下,这一成本增幅被显著的性能提升所抵消。
6. 优势与局限
优势
- 稳健的排列不变性:不受上下文顺序影响,适用于需要示例随机抽取的场景。
- 信息安全:避免标签泄漏,符合对 in‑context 学习的严格定义。
- 强大的长度泛化:在上下文数量变化时仍保持高性能,适合少样本学习与跨任务迁移。
- 兼容多模型:已在 GPT‑2、GPT‑Neo、Pythia 等不同架构上验证,方法本身与模型结构解耦。
局限
- 计算与内存略增:相较于最轻量的 AR‑ICL,注意力掩码与双倍输入导致约 1.5–2 倍的计算量,需在资源受限的环境中权衡。
- 实现复杂度:需要自定义 LOO 掩码与对称位置编码,对现有框架的改动较大,部署门槛稍高。
- 对称位置编码的设计:在某些特殊任务(如需要显式顺序信息)中,对称编码可能削弱必要的位置信号,需要结合任务特性进行调节。
7. 典型应用场景
- 少样本分类 / 回归:在仅有少量标注示例且示例顺序不可控的情况下,InvICL 能提供更稳定的预测。
- 跨域迁移:当训练与测试分布差异显著(如 OOD 任务)时,InvICL 的对称性与信息安全特性帮助模型保持鲁棒。
- 交互式提示系统:用户随意添加、删除或重新排列示例时,系统无需重新调参即可保持性能。
8. 小结
不变上下文学习(InvICL)通过 留一法注意力掩码 与 对称位置编码 的创新组合,成功实现了 排列不变性、信息不泄漏、上下文相互依赖 三大目标。理论上,它等价于在隐空间执行梯度下降;实验上,它在合成与真实任务上均显著超越传统 AR‑ICL 与其他不变 ICL 方法,尤其在 长度外推 与 跨域泛化 方面表现突出。尽管计算开销略有提升,InvICL 已成为提升大语言模型少样本学习稳健性的重要技术路线。
声明:文章均为AI生成,请谨慎辨别信息的真伪和可靠性!