在AR、VR、3D打印、场景搭建以及电影制作等多个领域中,获得高质量穿着衣服的人体3D模型变得至关重要。然而,传统的创建方法耗时且需要专业设备捕捉多视角照片,还依赖技术熟练的专业人员。
与此相反,浙江大学ReLER实验室的研究人员提出了一种名为SIFU的模型,该模型能够从单张图像准确重建3D人体模型,从而显著降低了成本并简化了独立创作的过程。

传统的深度学习模型用于3D人体重建通常需要经历从图像中提取2D特征、将2D特征转换到3D空间,以及将3D特征用于人体重建的三个步骤。然而,在2D特征转换到3D空间的阶段,过去的方法常常忽略了人体先验的引入,导致特征提取不充分,从而影响最终的重建结果。

为了解决这个问题,SIFU模型引入了侧视图条件隐函数,通过在2D特征转换到3D空间时加入人体侧视图作为先验条件,增强了几何重建效果。此外,在纹理预测的阶段,模型还引入了预训练的扩散模型,以解决不可见区域纹理预测较差的问题。
SIFU模型的运行分为两个阶段。在第一阶段,借助侧隐式函数,模型重建人体的几何和粗糙的纹理。在第二阶段,通过3D一致性纹理优化流程,模型对纹理进行精细化。这一流程中,作者设计了一种独特的Side-view Decoupling Transformer,通过全局编码器提取2D特征后,在解码器中引入人体先验模型的侧视图,使得在图像2D特征中解耦出人体不同方向的3D特征,从而用于重建。
实验结果显示,SIFU模型在几何重建和纹理重建方面均表现出色,不仅在全面多样的测试集上取得了最好的效果,而且在模型面对有误差的人体先验模型时依然具有较好的重建精度。
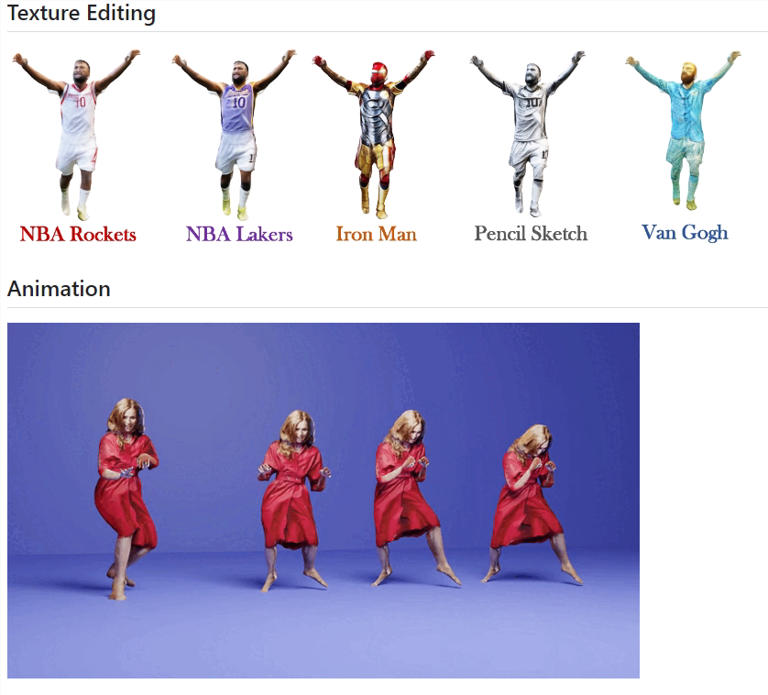
该模型的高精度和高质量重建效果使得其在3D打印、场景搭建、纹理编辑等领域具有广泛的应用前景。SIFU模型为单张图片人体重建提供了一种创新的方法,为未来的研究和实际应用提供了新的思路。
论文地址:https://arxiv.org/abs/2312.06704
项目代码:https://github.com/River-Zhang/SIFU